pandas多级索引根据求和项排序
需求描述
近期在项目实践中遇到此问题,GIS数据内容是某地的土壤类型分布图,其属性表中是每个图斑的面积,以及该图斑的土壤类型,从高到低包括土类、亚类、土属、土种四个级别的所述分类,属性表大致如下图所示(数据均为随机生成,分类及命名参考《土壤地理学》和《广东土壤》等资料):

要求导出属性表为xlsx后,按照土类、亚类、土属、土种分别进行分类汇总,每一级分类下均按照各项的总面积降序排序,同时要求水稻土排在最前,水稻土内的亚类按照土壤发育程度升序排列。
Excel实现
如果只是一次性实现,那么通过Excel的“数据透视表”功能很容易实现
插入数据透视表
拖拽设置数据透视表字段

设置依据求和项降序排列

完成

Pandas实现
由于不止一批这样的数据,且还有其它流程化的操作,于是希望能用Python实现,当然第一时间就是想到了Pandas这个库了,但是搜了一大圈之后发现貌似都没有找到能抄的作业,于是自己摸索了一下,现记录如下:
数据透视表
读入Excel文件就不多说了,Excel中数据透视表的功能在Pandas里面用pivot_table实现,代码很简单
attribute_df = pd.read_excel(AttributeExcel) # 读入Excel文件
table = pd.pivot_table(attribute_df, index=['TL', 'YL', 'TS', 'TZ'], values=['Shape_Area'],
aggfunc=[np.sum])pivot_table的详情介绍可参考Pandas文档
主要参数解释如下:
data:传入需创建数据透视表(汇总统计)的源数据DataFrame
values:需要汇总统计的字段名列表,例如本例中需要对面积进行汇总统计
index:汇总统计时的分组字段,可以是多个,那就是多级分组了,比如本例中的土类、亚类、土属、土种;除了分组之外,还充当索引的功能
aggfunc:汇总统计的方法(函数),例如本例中需要对面积进行求和,因此传入Numpy的sum函数
其它参数可参阅官方文档
多级索引排序
普通排序函数
上一步我们已经创建了一个多级索引的DataFrame了,排序用到的是sort_values函数,代码如下
table.sort_values(by=['SPTL', 'SPYL', 'SPTS', 'SPTZ'], ascending=False, inplace=True, key=lambda x: sort(x, table))也是十分简洁,一句话搞定,主要参数解释如下:
by:按什么字段排序,如果有多个那就依次排序,通过这样的方式我们就可以在保持上一步分组不变的前提下排序,而不是全部重新打乱统一再排序的效果
ascending:为true则正序,为false则倒序
inplace:为true则将排序结果应用到原数据集,返回None,为false则不改变原数据集,返回一个排好序的新数据集
key:叫什么好呢,排序的依据吧,就是如果此参数不为None,则按照此参数进行升序或降序排列,此参数也是我们功能实现的关键
另外还有一个sort_index的函数则是按照索引来排序,而不是按照值来排序了
排序key
这个key要求传入一个Series,来看看官方文档的表述
Apply the key function to the values before sorting. This is similar to the key argument in the builtin
sorted()function, with the notable difference that this key function should be vectorized. It should expect aSeriesand return a Series with the same shape as the input. It will be applied to each column in by independently.
在排序前对values应用此key函数。与sorted()函数中的key参数类似,需要注意两者的区别是此key函数应当是矢量化的。此key参数需要传入一个Series变量,且要求该Series变量与values输入的Series结构一致。此处传入的函数将会被独立地应用于values参数中的每一列。
实际上,按我个人理解来看,参考文档中体积的sorted()函数里的key参数,这里应该是一个函数,此函数接收一个Series,同时可以覆盖该Series中的值,以使Pandas按照该值来进行排序,所以说我们这里给它一个面积的值就对了。代码如下:
def sort(index, df):
length = len(index)
for i in range(length):
index_value = index[i]
index_level = df.index.names.index(index.name)
index_link_list = [slice(None), slice(None), slice(None), slice(None)]
index_link_list[index_level] = index_value
index_link_tuple = tuple(index_link_list)
data_series = df.loc[index_link_tuple]
sum = data_series[('sum', 'Shape_Area')].sum()
index[i] = sum通过这样的一个sort函数将传入的x(形参是index),是一个Series,逐个用面积和来赋值替换
特殊排序需求
正如开头所说,还需要水稻土排最前,亚类里面按发育程度排序,这时候就可以在后面进行一个人工赋值,代码如下:
if index_value == "水稻土":
index[i] = 9e9999
if index.name == "SPYL":
if "漂洗" in index_value:
index[i] = 10
elif "渗育" in index_value:
index[i] = 9
elif "潜育" in index_value:
index[i] = 8
elif "淹育" in index_value:
index[i] = 7
elif "潴育" in index_value:
index[i] = 6把水稻土的值设成一个比较大的数,让它的面积始终排第一,另外在亚类里面,也可以通过人工赋值按漂洗→渗育→潜育→淹育→潴育的方式进行排列。
去除索引导出
目前我们已经完成基本需求,导出结果大概长这样(用Excel模拟的)

最终我需要将其导出为下面这样
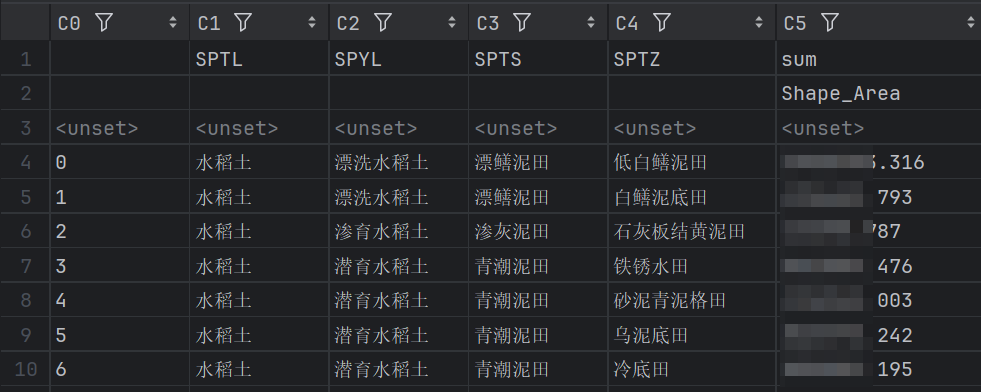
所以这里顺带记录一下去除索引的操作,去除索引后导出的就是上图所示,每一行的土类、亚类、土属、土种都是作为该行的一个数据,而不是索引的形式存在了
table.reset_index(inplace=True)小结
数据透视表
pivot_table排序
sort_values去除索引
reset_index
摸索过程
浅浅记录一下摸索的过程,希望能给自己以后的信息检索提供一个教训。一定要搜索专业名字,例如:多重索引排序。还有最好能直接找到官方文档进行阅读,详细看看每个参数的解释,很多博客(包括本文)或书籍都是根据内容需要,只解释与文章内容密切相关的参数,毕竟不是参考文档,也不适合把所有参数都详细列出来。查阅官方文档后,再结合debug看看返回值长什么样,就大概知道怎么做了。
查询AI时有的还是需要分步阐述需求比较容易找到,条件允许的情况下也可以把Excel文件上传到AI平台。只问一个最终问题,目前的AI回答很可能不符合预期。